We believe empowering engineers drives innovation.
We believe empowering engineers drives innovation.

My Summer Internship at Rearc Introduction & Background Hi, my name is Milan Patel. I am currently in 12th grade at Lenape Regional Highschool and I was a remote summer intern at Rearc from June to August 2023. AI Exploration Project General Problem Statement Given the abundance of datasets available to us, we always find it helpful to streamline idea generation. What does this dataset contain? What can I use this table for?

If you’ve been checking the news recently, you’ll have seen a lot of articles referencing shifting real estate trends around the world. The premise of many of these articles is that expensive, high-class office buildings that tend to be flagships of metro areas, are becoming less and less popular. As interest rates rise and work-from-home continues to become more common, one can only wonder how these real-estate trends will evolve from here, and the impact these trends might have on property owners.
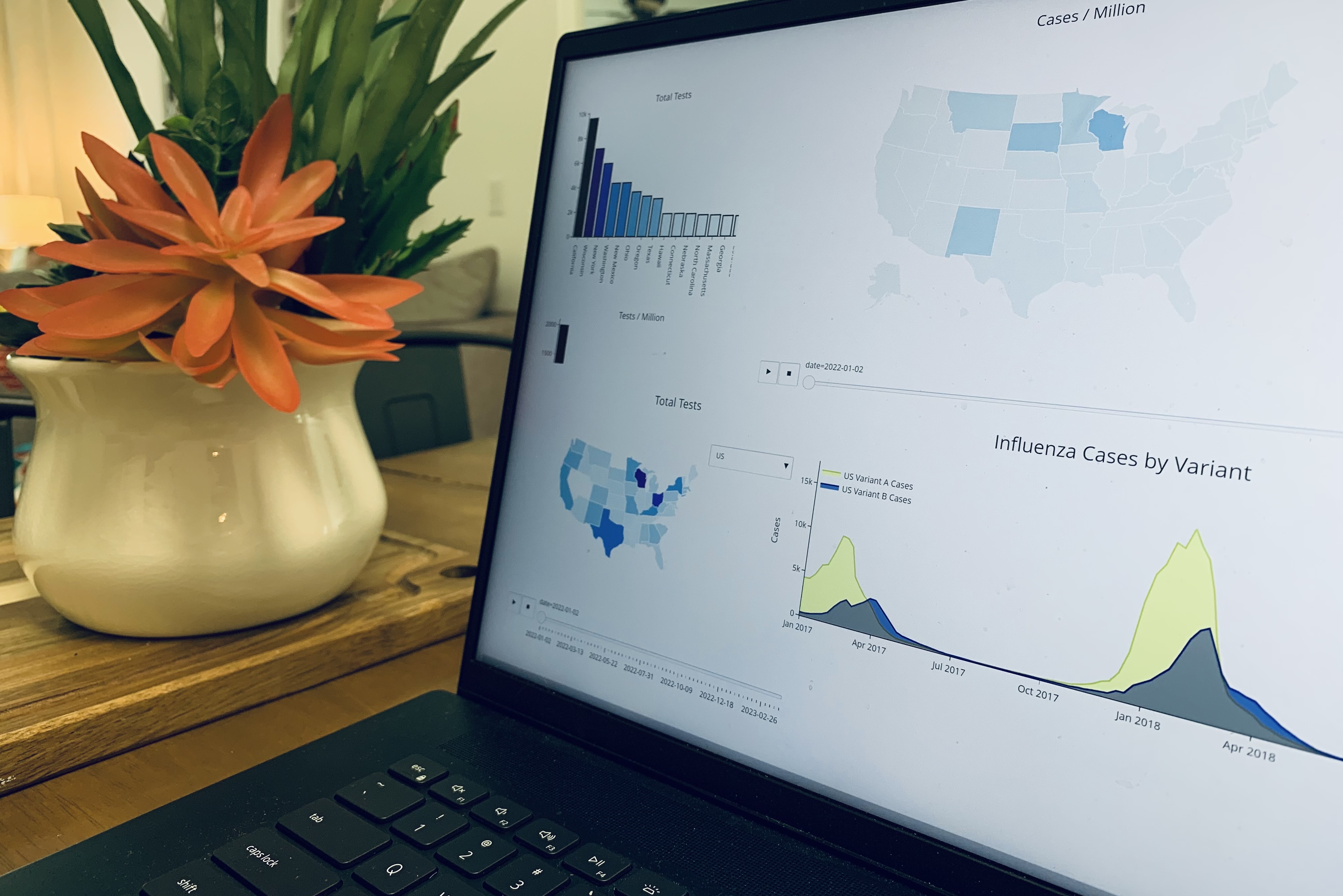
EpiLake Flu: Influenza Surveillance Data and its Applications Table of Contents Introduction Why Flu Data Matters Where is the Flu? Current Scope and Severity Diving Deeper: County-Level Data and Data Enrichment Anticipating Demand: Forecasting Insights Global Insights: Understanding Foreign Flu Seasons Conclusion Introduction Welcome to Rearc’s blog! We are a boutique consulting firm that is excited to bring a variety of business-ready datasets to customers. At Rearc, we are committed to helping our clients access the data they need to make informed decisions and be successful.
Introduction & Background Hi, I’m Mueez Khan. I’m currently an undergraduate Computer Science student at Rutgers University, and I was a remote summer intern at Rearc from June to September, 2022. In this article we’ll go over various projects and achievements during my internship at Rearc. About Rearc Rearc is a boutique cloud software & services firm with engineers that have years of experience shaping the cloud journey of large scale enterprises.

Flow logs are the native network logging layer for AWS. These logs can be setup specifically for logging IP traffic on subnets, network interfaces, or VPCs. VPC flow logs in particular contain a vast amount of IP traffic information and data points for our resources that can be leveraged for: Monitoring boundaries for networks and AWS accounts Detecting anomolous network activity Catching unintentional cross-region data transfers early (to avoid unnecessary costs) Identifying system optimizations based on AZ distribution Performing various network traffic flow optimizations In this blog post, we’ll be learning how to:

Performing any data migration at scale is a delicate calculation of technical complexities and cost. AWS has an extensive suite of database services to assist with these efforts in their Relational Database Service (RDS) offerings. In this post, we discuss the Aurora Global Database product and how it was used to migrate applications for a large financial media customer. We discuss the pros and cons of the product as it relates to other RDS offerings and why this was the best solution for our use case.
Apache Airflow is a phenomenal tool for building data flows. It’s reliable, well-maintained, well-documented, and has plugins for just about everything. It’s easy to extend, has pre-built deployment patterns, and is readily available in a variety of cloud environments. However, it’s also an aging tool, and has a few quirks that hearken to an earlier time in its development. Some issues include rigid DAG-centric dataflows, confusing differences between logical runtime and wall-clock execution time, and significant limitations in the size of individual DAGs.
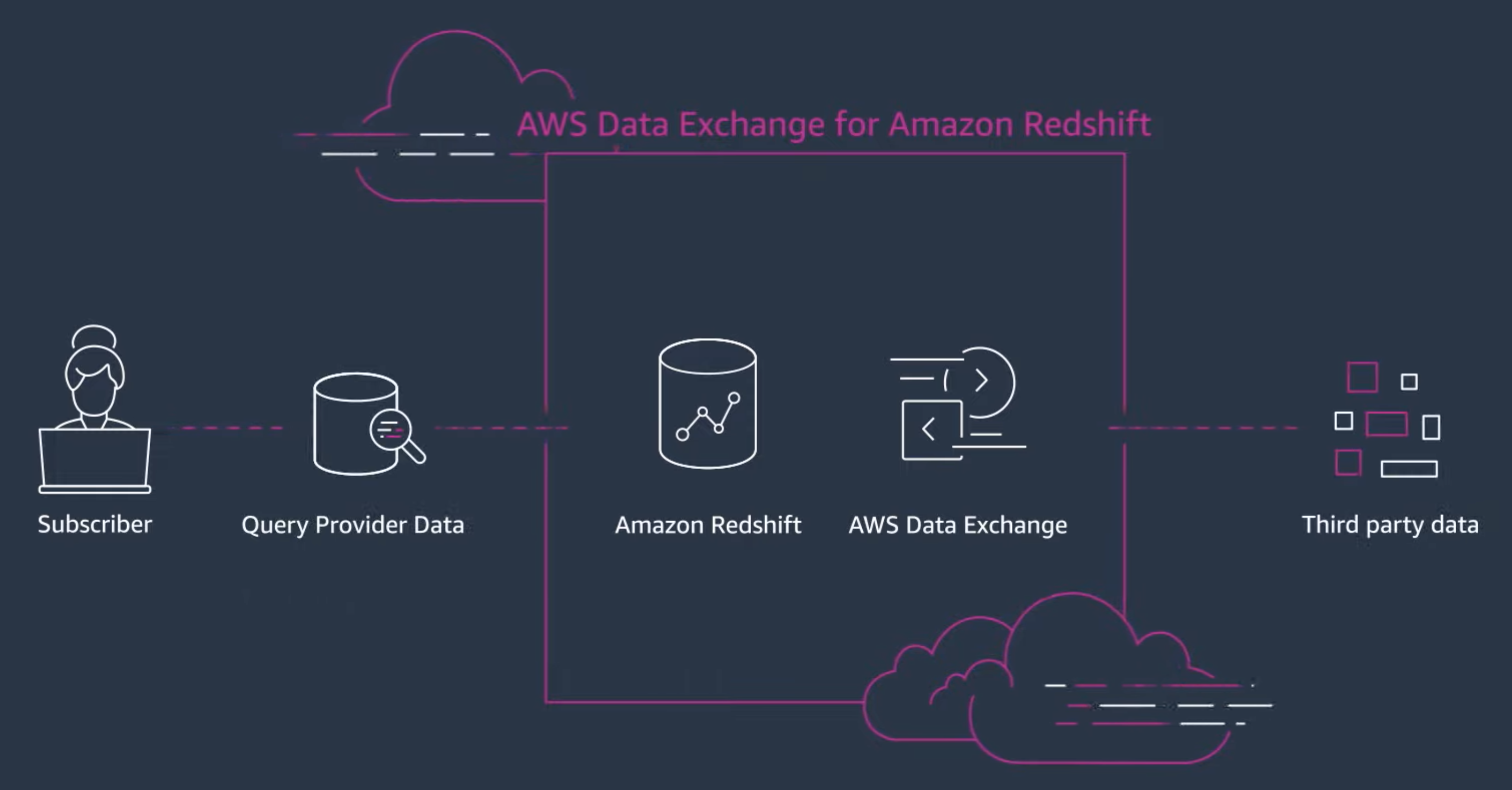
At Rearc we take pride in providing best-in-class curated data, delivering it “where the customer is.” That’s why we got very excited when Amazon announced AWS Data Exchange for Amazon Redshift. AWS Data Exchange for Amazon Redshift AWS Data Exchange for Amazon Redshift enables you to find and subscribe to third-party data in AWS Data Exchange that you can query in an Amazon Redshift data warehouse in minutes. This feature empowers you to quickly query, analyze, and build applications with third-party data.
At Rearc, we work with hundreds of datasets sourced directly from various authorities, government agencies, and organizations. A core part of the value we provide to our customers is ensuring that they receive clean and reliable data, no matter what the raw original data looks like. While some of this is accomplished by enforcing data types and strict schemas, errors can easily slip through the cracks. To address these problems, we began investigating solutions for a succinct, self-documenting, self-verifying way of declaring what the output data should look like.
We recently open sourced the Publisher Coordinator for AWS Data Exchange (ADX) to benefit the larger community of data providers and we are happy to share more details in this blog post. Rearc’s ADX Publisher Coordinator offers a scalable cloud-based infrastructure for data publishing process on ADX. If you are a data provider with valuable data offerings that you are excited to share with the world and monetize, keep reading!