We believe empowering engineers drives innovation.
We believe empowering engineers drives innovation.

Performing any data migration at scale is a delicate calculation of technical complexities and cost. AWS has an extensive suite of database services to assist with these efforts in their Relational Database Service (RDS) offerings. In this post, we discuss the Aurora Global Database product and how it was used to migrate applications for a large financial media customer. We discuss the pros and cons of the product as it relates to other RDS offerings and why this was the best solution for our use case. Finally, we will discuss how we used Route53 and Step Functions to achieve a fully automated failover solution.
At the start of this project, Aurora Serverless v2 was in beta and was not suitable for production deployments. Version 1 of this product did not support global databases at the time. I am happy to report that version 2 is now generally available and I encourage the reader to use global databases on top of this new solution so you can take advantage of elastic computing in addition to storage!
Our customer is running a hybrid cloud environment using a combination of AWS and on-prem infrastructure. The application side runs on Kubernetes in EKS, and the SQL data layer is on-prem. There is on-premise networking infrastructure that routes between the two infrastructure layers.
This has some pretty obvious drawbacks, the first being latency between the application layer and the database layer. If you have to leave the AWS availability zone every time you are doing database reads/writes, that can result in slower application performance. As our customer has their datacenter located in NJ, the application had to travel from Northern Virginia (where the us-east-1 region is located) to New Jersey for any database reads and writes. Below is a table that shows this latency difference between the local and remote site.
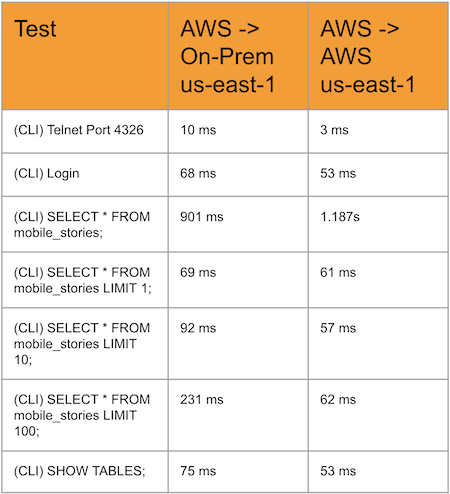
The second drawback is costs. AWS charges for outgoing network bandwidth so if apps send a lot of high-throughput write traffic to the database, that will add up in your bill each month. Additionally, Aurora scales up database storage elastically, so you only pay for the data you are using. This saves you from having to calculate how much storage to buy and eases the upfront storage costs with moving to a new database.
Lastly, there were drawbacks in the backup architecture on-premises with regards to availability and RPO times. With Aurora Global Database, you are getting high availability and reliability through the ability to deploy across multiple availability zones and regions. As we will show, it takes some extra legwork to obtain high availability across regions in case of a total region failure, but it is able to be covered using a variety of other AWS services.
Given the customer’s requirements of wanting a highly available, reliable, and multi-regional database solution, Aurora Global Database was the best fit to satisfy these requirements. During the initial research phase, we unearthed some pros and cons of the product as it relates to other RDS products that drove some of the future implementation decisions. Some of these are listed below.
| Pros | Cons |
|---|---|
| Multi-AZ Deployments | No Global DNS Endpoints |
| Multi-Region Deployments | No Multi-Master |
| Elastic Storage | No Automated Unplanned Failovers |
| Low RPO Time | No Backtracking |
| Global Reads | |
| Lots of Useful Metrics |
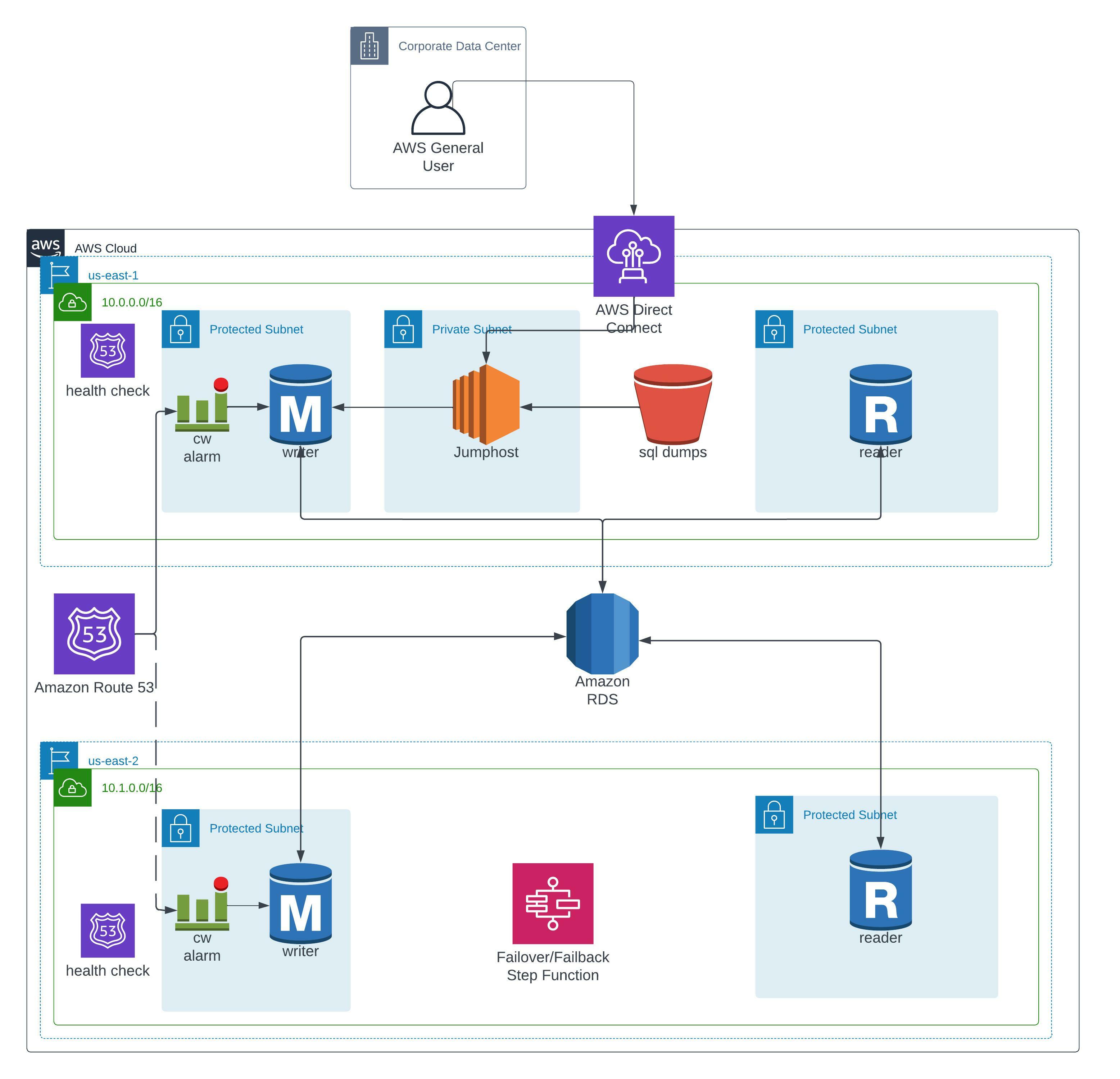
The solution we proposed is outlined in the diagram below. In this case, we are using two regions for this deployment (us-east-1 and us-east-2).
At Rearc we use Terraform pretty heavily to deploy and manage cloud infrastructure. As is customary for any infrastructure project, it’s a good idea to check if a public module has been made first. I usually find good ones in this organization of repositories. In there, I was able to find inspiration from the aurora module to create a custom module for our customer which satisfies their infrastructure needs for the data migration. Some of the additions and customizations that were made are detailed below.
One product that works well with Aurora Global Database is the AWS Key Management Service (KMS). About a year ago, they released the ability to create multi-region keys, which greatly simplified creating KMS encryption solutions that span multiple regions. It’s pretty easy to configure this in Terraform, as pictured below.
resource "aws_kms_key" "primary" {
description = "Primary Aurora Global Database KMS key for ${var.name}"
deletion_window_in_days = 10
multi_region = true
key_usage = "ENCRYPT_DECRYPT"
}
resource "aws_kms_replica_key" "replica" {
provider = aws.secondary
description = "Multi-Region replica key"
deletion_window_in_days = 10
primary_key_arn = aws_kms_key.primary.arn
}
Additionally, you can use AWS Secrets Manager to do automated password rotations for RDS databases in both PostgreSQL and MySQL. Amazon provides Lambda function code that can rotate the passwords on a set schedule, which you then set in Secrets Manager. The list of lambda functions can be found here.
It is generally a good idea to place databases in subnets that have no egress internet access and only allow ingress access from subnets in your VPC. This way, you can ensure that your databases are private from the outside world. We were able to programmatically ensure that using the following Terraform code. Using tags, we were able to filter out the subnets we needed:
data "aws_subnets" "primary_private" {
filter {
name = "vpc-id"
values = [var.primary_environment.vpc_id]
}
tags = {
SubnetTier = "Private"
}
}
Security groups were also created for the database that only allowed the port being used for SQL (4326 etc) from our VPC subnets. Aurora provides a writer and reader endpoint with each regional cluster you create so that your apps don’t need to be aware of what goes on underneath (instances get replaced, availability zone failovers, etc).
Aurora Global Database comes with automated backups out of the box. However, it comes with a few limitations:
No cross-region capabilities
Gets deleted along with database cluster
Thus, we decided to augment this solution with the AWS Backup offering from AWS. This allowed us to create backups at multiple time frequencies (every hour and day) and gives you the capability to copy your snapshots to vaults in differing regions. A picture of the architecture is below.
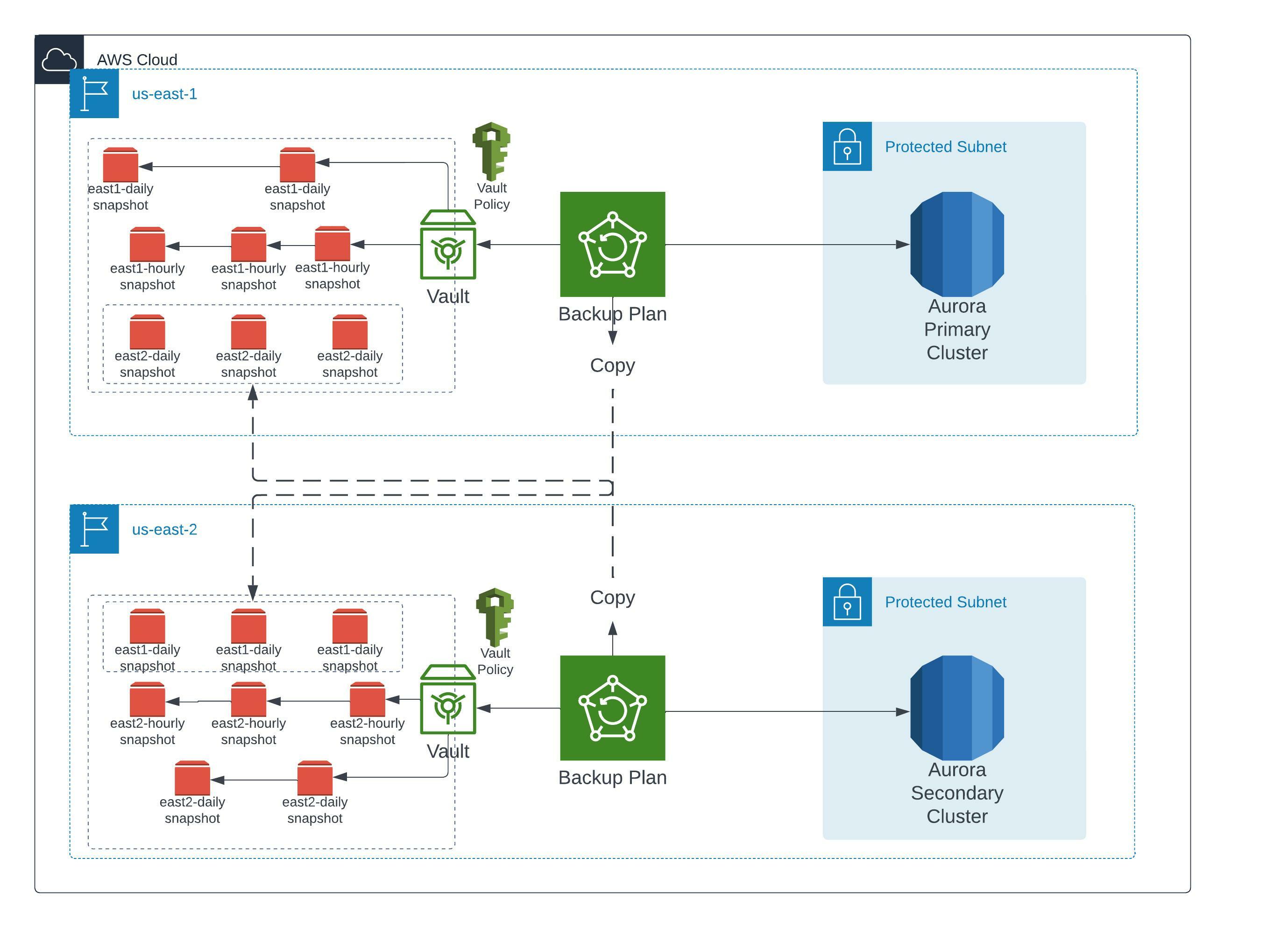
This plays nicely with global databases because you can ensure that regardless of where the writer (primary) cluster is, you can ensure backups are being created in case of data corruption or loss. Doing this also separates the database from the backups, so you can delete the database and its backups can be retained for a long time. On that point, AWS backups lets you store snapshots for up to 10 years! Finally, you can use vault access policies to control how other IAM entities in your account can access your backups. So overall, it’s a much more comprehensive product than the offering that Aurora comes with.
One difficulty in using Aurora Global Database is dealing with DNS resolution at a global level. The service only comes with regional writer/reader endpoints. Our customer had a specific requirement that they not have application code changes when a failover occurs. This meant that we had to design a custom solution to handle both managed and unplanned failovers and keep applications running seamlessly. We were able to achieve this using Route53 and Step Functions. You can take a look at how Route53 is set up by referencing the architecture image at the top of the post.
Route53 was a good choice due to its ability to provide failover routing, and Route53 is a global service which means it is not affected by regional outages. We utilized Route53 health checks that point to Cloudwatch alarms. These alarms are set to alert on the AuroraGlobalDBReplicationLag metric, which tracks how far behind the secondary cluster is with respect to data replications. We exploit the fact that this metric only exists for secondary clusters, so they come in as unhealthy and are not routed to. Conversely, the value will be 0 for this metric for the primary cluster. A Terraform example of how a Cloudwatch alarm can be wired to a Route53 health check is below.
resource "aws_cloudwatch_metric_alarm" "us_east_1_replica_lag" {
alarm_name = "${var.name}-${var.tags.environment}-aurora-global-db-replica-lag"
comparison_operator = "GreaterThanOrEqualToThreshold"
evaluation_periods = "3"
metric_name = "AuroraGlobalDBReplicationLag"
namespace = "AWS/RDS"
period = "60"
statistic = "Average"
threshold = "0"
alarm_description = "This will be monitored as a route53 health check to determine where to route database queries"
actions_enabled = false
treat_missing_data = "missing"
dimensions = {
DBClusterIdentifier = "${var.name}-${var.tags.environment}-primary"
}
}
resource "aws_route53_health_check" "us_east_1_is_primary" {
type = "CLOUDWATCH_METRIC"
cloudwatch_alarm_name = aws_cloudwatch_metric_alarm.us_east_1_replica_lag.alarm_name
cloudwatch_alarm_region = var.primary_environment.region_name
insufficient_data_health_status = "Healthy"
}
To actually call the AWS API for Route53 and RDS, a step function was created that handled performing both unplanned and managed failovers. The difference between the two is discussed in this aws documentation. There are many ways to use step functions, but here it is being used to run a sequence of Lambda functions that call boto3 APIs. The design of the step function is pictured below.

Step functions is a fairly complex product that has tons of features. Luckily, it is supported by Terraform and we were able to use this resource combined with the lambda module to fully automate the deployment of the step function. Using step functions and Route53 together, we were able to achieve fully automated managed and unplanned failovers without any changes to application code.
The datasets that were to be included in this migration were not terribly large, so we went with a lightweight strategy which included using an EC2 jumphost, S3 buckets, and sql dumping functions from both mysql and postgresql (called mysqldump and pg_dump). The workflow is as follows:
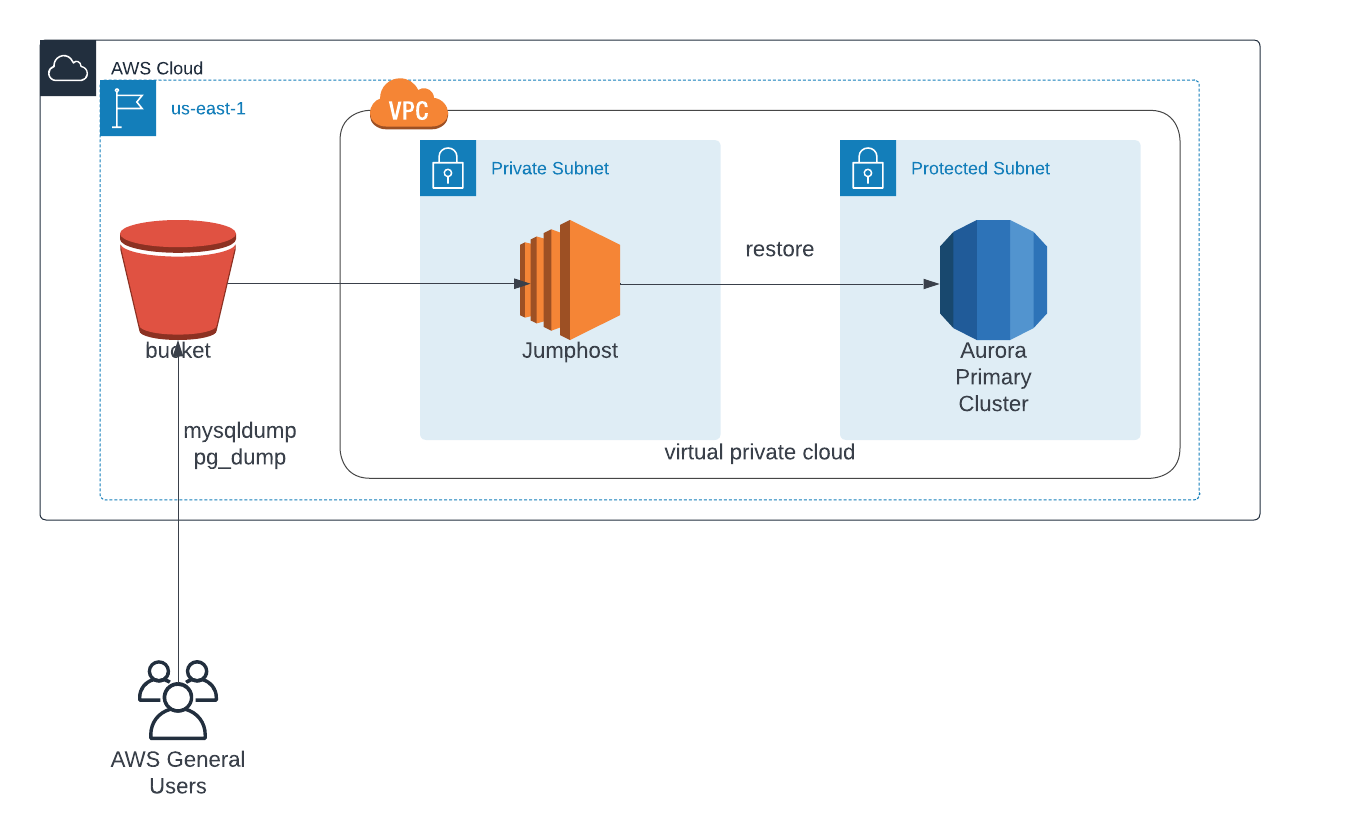
It is worth noting that this method does incur some downtime, as you need to ensure that applications are not writing to the old database while you are migrating to the new one. There are other methods like using the AWS Database Migration Service (DMS) that allow you to do more of an active migration. Just be aware that it is more expensive and may be harder to implement in environments where you have tight networking security.
The biggest pain point of using Aurora Global Database was that it does not come with a global DNS solution. This means that applications have to manage changes to the underlying regional endpoints in case of failovers or database name changes. Our customer had assumed the service came with this functionality, and communicating that the product couldn’t meet their needs without more work pushed our timelines back. Nonetheless, we were able to overcome this and still deliver a solution that met their needs.
Another pain point of the solution is that implementing our global DNS solution as explained above meant that restoring from backups was painful as well, as you need to essentially create an entirely new database. Once that database is created, you have to manually configure it to work within Route53’s endpoints that you have created so that applications can talk to it. It is a manual process that can take hours.
Finally, the last learning is really more personal. When communicating these solutions to customers, it is good to make sure they have a full understanding of the solution you are proposing. There were some assumptions made about the product by our customer that turned out to be wrong, and their expectations had to be adjusted accordingly. They were not aware of these limitations when we suggested the product to them as a solution. Ensure that you are emphasizing both the pros and cons of solutions so that everyone understands the work that needs to be done.
In conclusion, we have found Aurora Global Database to be a compelling solution to run applications requiring highly available and reliable data layers. Even with some of the shortcomings discussed above, the AWS API allows you to work around this using some other products that work well together. In our pilot tests, our customer has been happy with all of the benefits that have been provided over their on-premise solution.