We believe empowering engineers drives innovation.
We believe empowering engineers drives innovation.
Hi, my name is Milan Patel. I am currently in 12th grade at Lenape Regional Highschool and I was a remote summer intern at Rearc from June to August 2023.
Given the abundance of datasets available to us, we always find it helpful to streamline idea generation. What does this dataset contain? What can I use this table for? How can we utilize this data to meet a customer’s needs? This can be a very time-consuming process, and we need to be agile in meeting various requests.
My approach to this was to create a model that could not only generate analytics for business purposes but also create examples of products to build with a given dataset using the OpenAI GPT API. The purpose of developing this is to use AI to make our job easier in the sense that we can have another brain or tool to be used as a brainstorming device.
I came across some challenges with this such as getting the AI to respond in a useful way. When inputting a prompt into Chat GPT, the answer will be more accurate the more descriptive you are with your prompt. Since we have a limited amount of prompts per minute I had to build one large prompt based off multiple answers given by the user.
Another issue that I came across with the version of the OpenAI GPT Model that we were using was the fact that it had a limited amount of tokens or characters that were able to be input. Currently, we are using the gpt-3.5-turbo version which allows a maximum amount of 4096 tokens. However, I realized that we didn’t need the whole data set, we just need a general picture of what it looked like to feed to the program. The perfect solution for this was to use the pandas library and grab a random set of 10 rows from the whole data set so that we could have a good estimate of what our model consists of without going over the character limit.
To set up the OpenAI API I needed first to have an account that could access API keys. To build it in my code I needed to import the “openai” library. After that I needed to generate a valid API key from https://platform.openai.com/playground. Then I could use it in my code and choose the GPT model I have purchased on my Open AI account.
Here is an example:
To test the program I used the Japan vaccinations data set that Rearc was currently working with. In order for the tabular data to be uploaded to the GPT Model, I needed to convert it to JSON format using the “pandas” library.
Here is an example of how to that:

Here are the first 10 random rows of the data set printed from the df.head() function above:

The user is prompted with 2 questions to start the program off. In this case I chose prompt 1. Prompt 2 (the general question), would only be used to locate certain values within the data set.

Then the user is asked various questions to provide context and build a better answer from the AI.

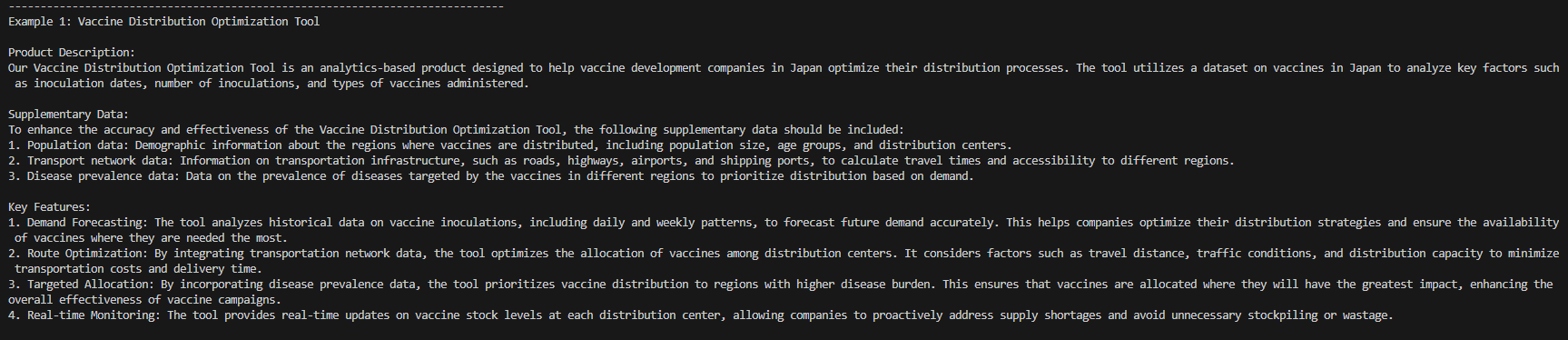
An output of this program would give you 2 examples of potential use cases of this data. It would provide information such as production description, supplementary data and key features. In this case I will only show 1 example to minimize redundancy.
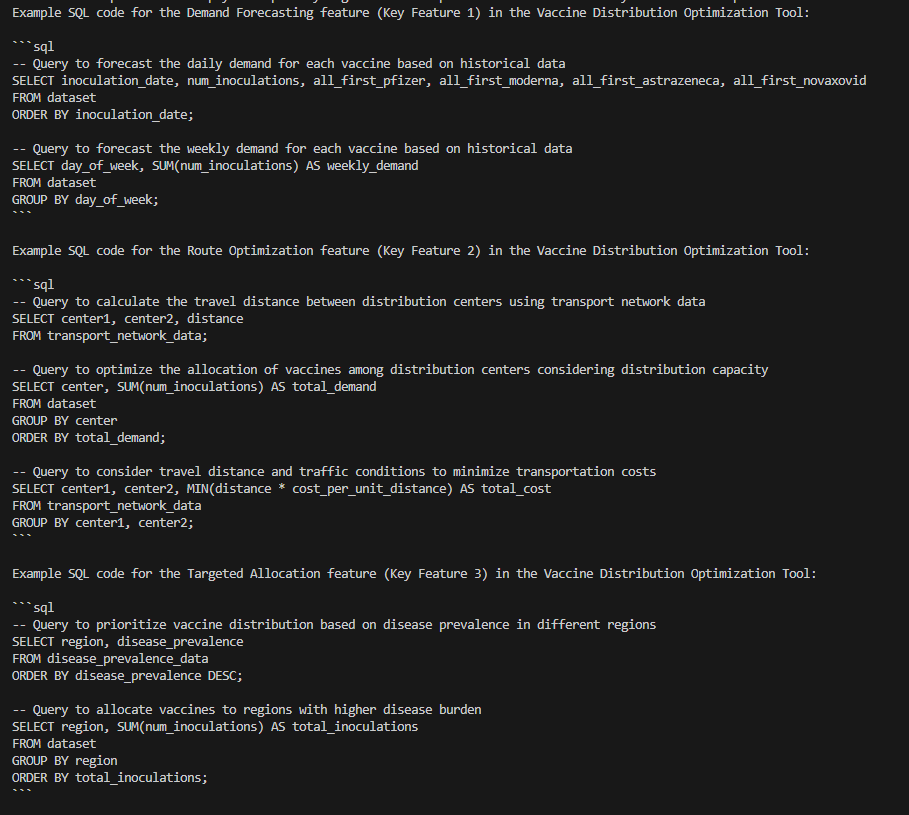
The SQL code is also provided as a follow up.
We can use this program as a tool to create ideas for product development and give a variety of useful responses. Instead of someone having to read all the data and take hours to make ideas, the AI can do it within minutes. We can easily explore the data, finding trends and extract valuable pieces of information that we need from the companies we are working with. Finally with this program we can now use the power of the AI to improve product lists with potential customer use-cases, quickly and efficiently.
I will now be going into my senior year of high school focusing on learning as much as I can about AI and Data Analytics. I want to thank my entire team at Rearc for giving me this opportunity and I will take what I have learned here as one of the first steps to building my future in this field.
