We believe empowering engineers drives innovation.
We believe empowering engineers drives innovation.
Leaderboard benchmarks show competitive offerings.
In the rapidly evolving world of artificial intelligence, a new contender has emerged at the forefront of chatbot technology. Anthropic’s Claude 3 Opus, a large language model (LLM), has recently claimed the top spot in the Chatbot Arena, surpassing the previously dominant GPT-4. This development marks a significant shift in the AI landscape, suggesting that OpenAI may no longer hold the undisputed leadership position in the industry.
The Chatbot Arena, a platform created by Large Model Systems Organization (LMSYS Org), affiliated with the University of California, serves as a battleground for LLMs. It employs a unique crowdsourced approach to testing, where human participants rank the outputs of various LLM models. This method ensures that the evaluations are based on real-world user experiences, providing a true-to-life reflection of each model’s performance than synthetic benchmarks. To maintain objectivity, the Arena uses a system where two randomly selected LLMs are given the same user prompt, and the users are not shown the names of the LLMs till after the voting process. This approach helps to avoid bias and ensures that the rankings are based solely on the quality of the responses.
LMSYS compiles the data from these human evaluations into a leaderboard, utilizing the ELO ranking system to rate the AI models. The ELO system, originally designed for chess and widely used in competitive gaming, measures player performance based on the outcomes of matches against opponents of varying skill levels. This system has proven effective in assessing the relative strengths of AI models, offering a dynamic and responsive method for ranking.
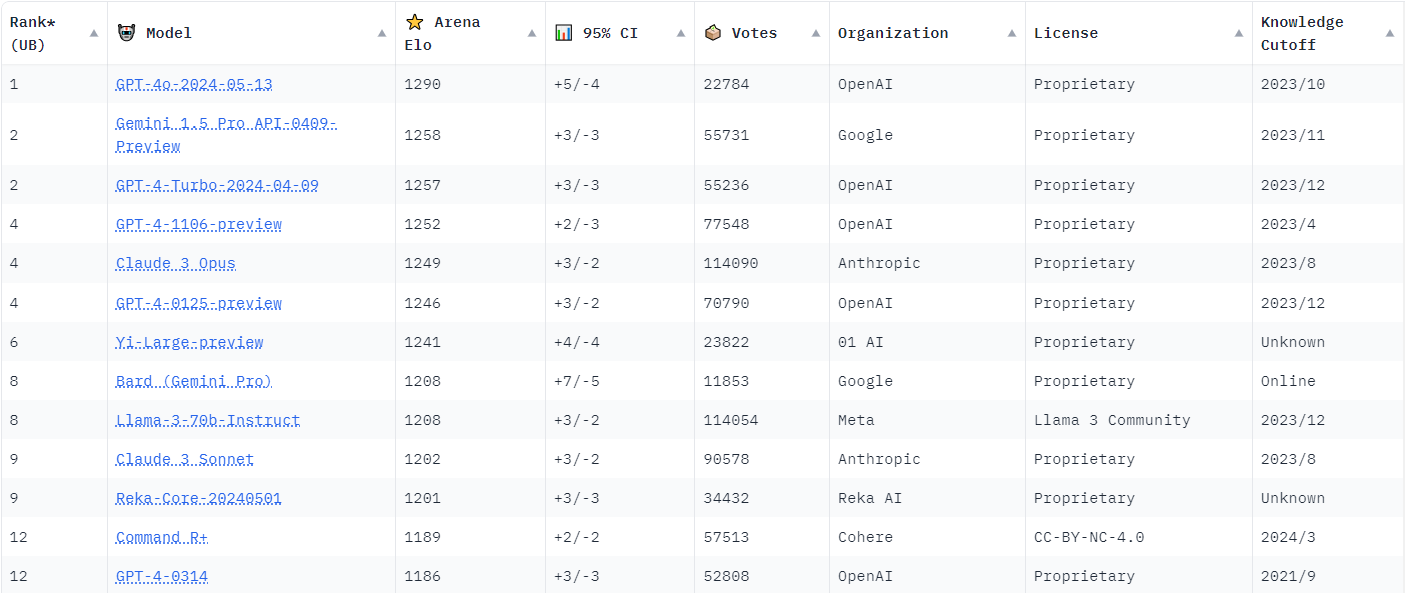
Source: LMYSY leaderboard [May 28, 2024]
In the rankings, Claude 3 Opus achieved a score of 1253, narrowly edging out GPT-4, which scored 1251. This essentially ties LLM quality in the eyes for the user and underscores the fierce competition in the AI space.
Anthropic’s Opus is also competitive in both pricing and larger context length. This model, along with Haiku and Sonnet, form a trio of LLM’s released by Anthropic, each with distinct model sizes that influence their pricing, operational speed, and problem-solving capabilities. For instance, larger models like Opus are capable of tackling more complex problems but require more computational resources, which in turn increases their operational costs compared to the smaller models Haiku and Sonnet. All three offer very large context lengths of 200,000 tokens, and Anthropic notes select customers get the ability to use one million tokens.
Lets compare the existing OpenAI offerings with Anthropic’s
| Provider | Model | Size | Context Length | Tokens / Second | Input / 1M tokens | Output / 1M tokens |
|---|---|---|---|---|---|---|
| OpenAI | Gpt-3.5-turbo-0125 | Small | 16k tokens / 4k output | 55 | $.50 | $1.50 |
| Anthropic | Haiku | Small | 200k tokens** | 101 | $0.25 | $1.25 |
| OpenAI | Gpt-4-turbo-2024-04-09 | Medium | 128k context | 20 | $10.00 | $30.00 |
| Anthropic | Sonnet | Medium | 200k tokens** | - | $3.00 | $15.00 |
| OpenAI | Gpt-4-0613 | Large | 8k tokens | - | $30.00 | $60.00 |
| OpenAI | Gpt-4-32k-0613 | Large | 32k tokens | - | $60.00 | $120.00 |
| Anthropic | Opus | Large | 200k tokens** | 28 | $15.00 | $75.00 |
** limited customer access to inputs exceeding 1 million tokens.
Updated May 10, 2024
The release of Anthropic’s Claude 3 Opus marked a significant milestone in the AI industry disrupting the market leader. While OpenAI was able to launch a new revision to retake its ranking, it shows competition between providers brings consumers better LLM’s.
Overall, the most positive take way being OpenAI is not the sole option and companies implementing GenAI should undertake design’s with the top ranking LLM providers considered.
