We believe empowering engineers drives innovation.
We believe empowering engineers drives innovation.

Prompted by an uptick in high profile outages, one product engineering team at a global investment bank began to explore options for increasing the resiliency of their services.
With a certainty of rapid growth as the team prepares to onboard product data and consumers from several disparate teams across the firm, the team began to look towards a migration to Amazon Web Services for their unified platform. Comprised of a small handful of specialized software engineers, experts in their domains but unfamiliar with cloud infrastructure, the product team engaged with Rearc to solve their needs.
In the firm data centers, the product runs across a spread of compute providers and data stores. Linux virtual machines managed by a separate team host the core Java APIs and Apache Ignite cluster, while an in-house-managed Kubernetes cluster provides the platform for the React user interface, Node.js presentation API, and Django administration API. A managed on-premise MongoDB instance serves as the primary data store, and events from the application are streamed to topics in an on-premise Apache Kafka cluster.
The process of increasing compute capacity within the organization is not on-demand, but requires a request and approvals process that can last up to two months, followed by an additional two to three month period of waiting for delivery and installation of the newly requested servers. For an identified need of additional capacity in January, it could be May or June before that request is complete.
Fronting the core APIs for the application is a HAProxy instance. This instance performs the TLS offloading for service connections as well as layer 7 routing logic, which was primarily a proactive response to expected scaling issues. Working with organizational bounds, a load balancing scheme was devised where CRUD traffic to the core APIs is directed to separate read and write pools running the same application. The pools were sized to expected peak load, yet due to the bursty nature of consumer traffic, sit idle a majority of the time.
Compounding these scaling issues were the limited monitoring options available to the team. With the tools available, it is not always clear to the product team where the bottleneck lies in their application stack.
Without clear visibility into their infrastructure, capacity planning and what to scale during periods of high traffic are questions that the product team can’t easily answer. Combine this with the arduous process of requesting additional compute resources, and the team finds themselves spending considerable resources on a peak load that may not arrive for another two quarters.
Given the team’s existing familiarity with containerization practices, on-demand scaling, and the need for low operational overhead, ECS on Fargate and EKS on Fargate were immediately strong contenders. While both ECS and EKS meet the primary requirements of scalability and monitoring via CloudWatch, Apache Ignite provides better cluster discovery mechanisms for Kubernetes, making the increased complexity a balanced tradeoff in the context of the team’s existing familiarity.
The existing use of an on-premise MongoDB cluster lends to a natural first selection of DocumentDB in a migration to AWS. However, in an internal evaluation the team found MongoDB features related to several functional operators that were not compatible with DocumentDB. MongoDB Atlas on AWS provides 1:1 compatibility with MongoDB, while abstracting scaling, backups, maintenance, and multi-region failover. MongoDB Atlas on AWS also provides PrivateLink endpoints and authentication integration with AWS IAM, keys to meeting the security requirements set forth by the client’s risk management strategy.
To support an active/active resiliency strategy for EKS and MongoDB Atlas, the team chose two well-supported regions to stand up their infrastructure. Traffic is split between both regions, weighted heavily towards the primary write region for MongoDB Atlas. In a fail-over event, the application does not need to transfer state, and MongoDB Atlas manages the election of a new primary node without intervention.
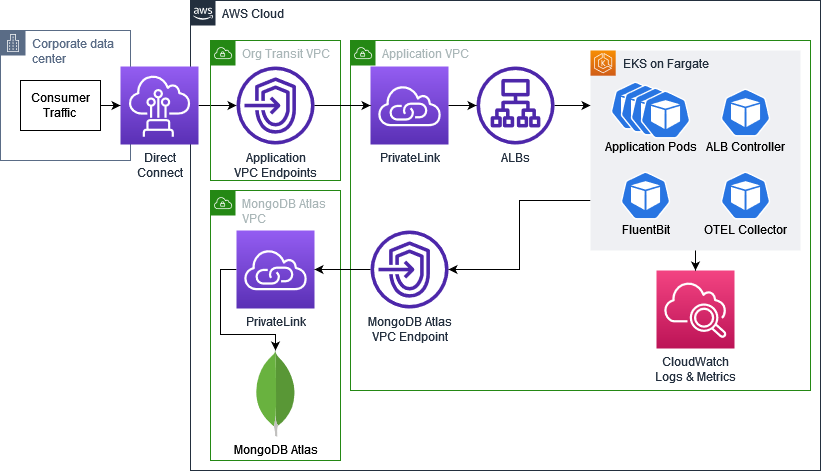
The firm’s strict risk tolerance drives much of the network architecture for this migration: no internet ingress or egress is permitted, and all consumer traffic will reach the applications from on-premise via the organization’s existing Direct Connect. All traffic to MongoDB Atlas and AWS services is encrypted in transit and moves via VPC Endpoints.
Application access is given to the organization’s transit VPC via PrivateLink, behind which is an Application Load Balancer (ALB). This ALB performs TLS offloading using ACM certificates uploaded from the organizations private CA. The ALB also offloads UI authentication using the organization’s OIDC provider to both standardize how the application authenticates users without on-premise identity resources and reduce the application team’s development overhead. Attaching new pods to listeners as Fargate scales is solved by the AWS Load Balancer Controller, which updates Target Group Bindings dynamically.
In addition to the AWS service’s native integration with CloudWatch Logs and Metrics, FluentBit was set to stream all container logs from the EKS clusters to CloudWatch Logs, and the AWS Distro for OpenTelemetry Collector (ADOT Collector) was enabled to send pod metrics to CloudWatch.
With AWS EKS on Fargate and Kubernetes Horizontal Pod Autoscaling, the team is enabled to scale their application in response to real-time metrics pushed to CloudWatch by the ADOT Collector. The option now exists to scale their core API by request load, Ignite by memory usage, and even custom metric scaling is only a small change away. MongoDB Atlas also scales compute and storage without intervention, staying within predefined cluster size guardrails to protect budget.
Time to scale is measured in seconds on AWS, a massive improvement over the six-month process before.
A far cry from the org-managed monitoring options on-premise, the team now has access to CloudWatch Logs and Metrics for all integrated AWS services and all of their application custom metrics in one place, with no development overhead necessary, thanks to the ADOT Collector. Discreet metrics across multiple tools on-premise numbered 55 and increased to over 1,500 (+2,750%) with CloudWatch Metrics, and logs, which were not centralized previously, are now consolidated in one location.
With AWS, the team is now empowered with the visibility to see what’s happening with their application near real-time and make intelligent decisions about their product using the latest data.
Perhaps the largest non-quantitative benefit for the team is bringing control over the entire product stack within the team. Previously, requests to separate teams for debugging access, database logs, or networking changes could take precious time during an incident. On AWS, human interactions previously necessary for scaling are eliminated, and the application team has immediate and total access to their environments to make changes at the speed of consumer demand.
Rearc is an AWS Advanced Consulting Partner that helps customers achieve faster innovation through cloud-native architectures on AWS, DevOps culture transformations, data engineering, and enabling engineering teams to reach their full potential.